Добавляем колонки
Иногда нам может потребоваться добавить новые колонки к уже существующим записям в DataFrame. Это может быть совершенно новая информация или полученная в результате расчёта на основании уже имеющейся в нашей таблице.
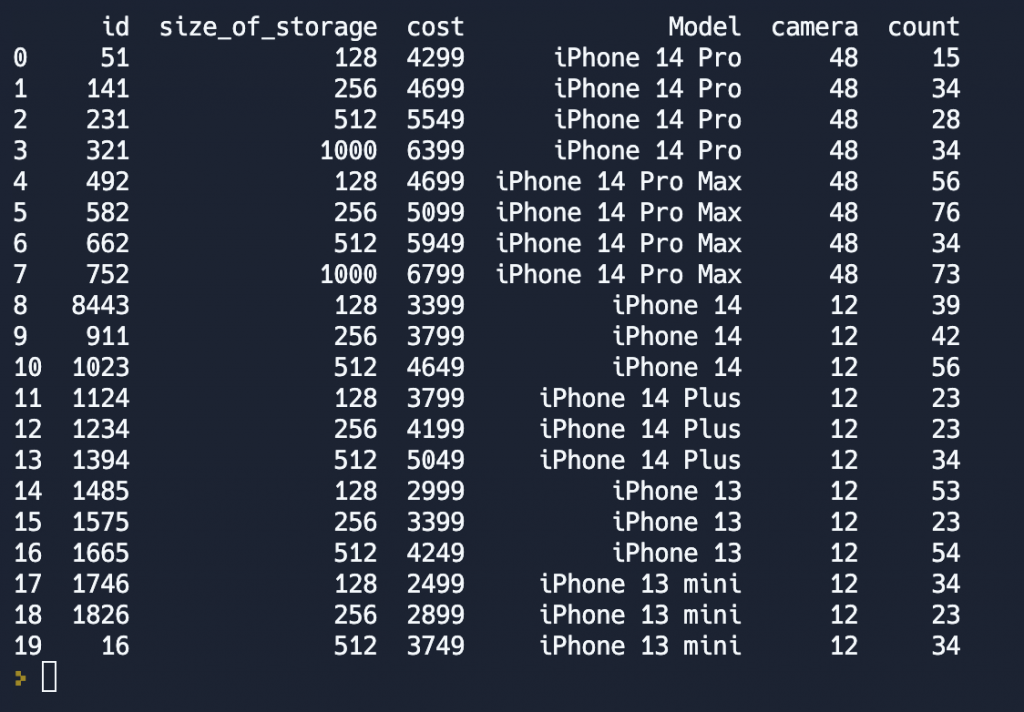
Один из способов — это передать список с количеством элементов равным количеству рядов DataFrame. Допустим, к нашей таблице с телефонами мы хотим добавить ещё один столбец, который будет хранить информацию о количестве в магазине. Назовём столбец count.
import pandas as pd
df = pd.read_csv('iphones.csv', sep=';')
df['count'] = [15, 34, 28, 34, 56, 76, 34, 73, 39, 42, 56, 23, 23, 34, 53, 23, 54, 34, 23, 34]
print(df)В результате у нас в DataFrame последним столбцом теперь хранится информация о количестве товара.
Если мы хотим добавить столбец и заполнить его одинаковыми значениями, не обязательно создавать список с одинаковыми элементами. Достаточно просто указать это значение.
df['has_esim'] = TrueВ результате работы этого кода у нас добавится столбец has_esim и заполнится значением True для каждого товара.
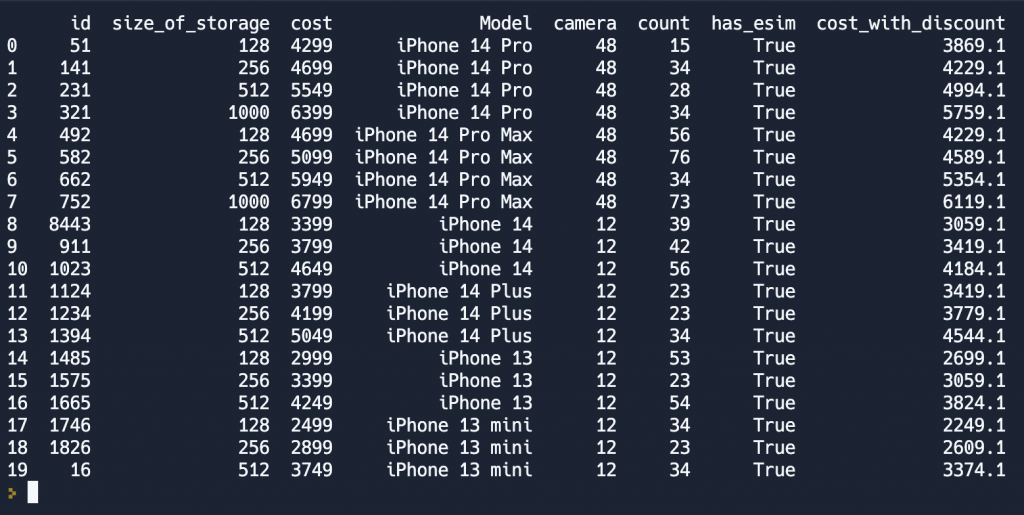
Но также мы можем создавать новые столбцы и наполнять их значениями уже на основании имеющейся у нас информации. Давайте создадим колонку, в которой будем хранить стоимость каждого продукта на период новогодней распродажи. Назовём колонку cost_with_discount, а размер скидки для каждого продукта у нас будет 10 процентов.
df['cost_with_discount'] = df.cost - df.cost * 0.1В результате всех манипуляций мы получим вот такую таблицу.
Данные о скидке выглядят не очень-то красиво. Хочется отрезать дробную часть и получить только целое значение. Мы знаем, что в Python есть функция int(), которая поможет преобразовать в целочисленное значение. Для того, чтобы применить эту функцию ко всему столбцу, используем метод apply(), который в качестве параметра принимает название функции или метода, который необходимо применить к каждому значению в указанном столбце. Важно отметить, что метод apply() не изменяет сами данные в столбце, а возвращает новую серию данных, которую мы должны перезаписать.
df.cost_with_discount = df.cost_with_discount.apply(int)Аргументом метода apply() могут выступать не только встроенные функции, но и те, что мы написали самостоятельно. Давайте представим, что перед нами стоит следующая задача. К началу новогодних распродаж на полках магазина каждой модели телефона должно быть не меньше 30 штук. Нужно узнать, каких моделей и сколько нам необходимо заказать, и записать эту информацию в столбец quantity_to_order. Проблема реализации этой задачи заключается в том, что некоторых моделей у нас присутствует сполна, поэтому представленный ниже код будет неверным.
df['quantity_to_order'] = 30 - df['count']Так как в результате мы получим отрицательные значения вместо нуля у тех моделей, наличие которых больше 30.
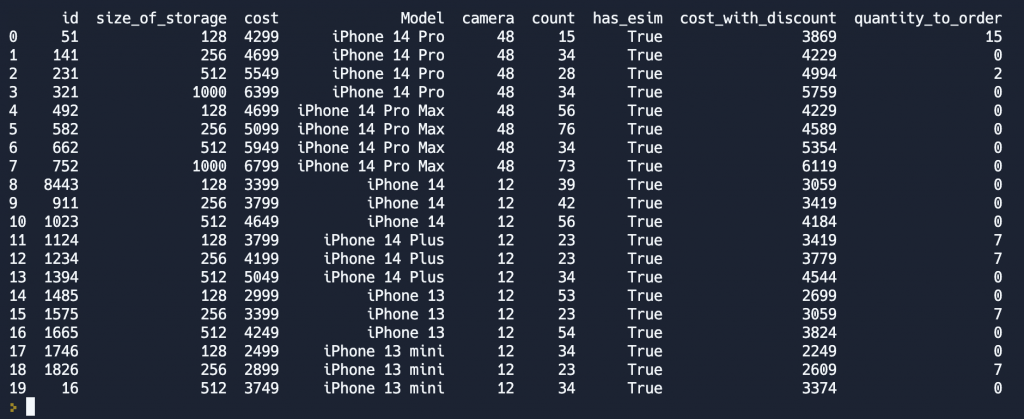
Для того, чтобы реализовать поставленную задачу, для начала, объявим функцию eval_order, в параметр которой будет передано значение хранимое в ячейке таблицы. А после применим эту функцию к каждой ячейке столбца count и сохраним результат в новом столбце quantity_to_order.
def eval_order(value):
if value > 30:
quantity = 0
else:
quantity = 30 - value
return quantity
df['quantity_to_order'] = df['count'].apply(eval_order)Результат мы видим ниже
Точно такой же результат мы можем достичь используя функцию lambda.
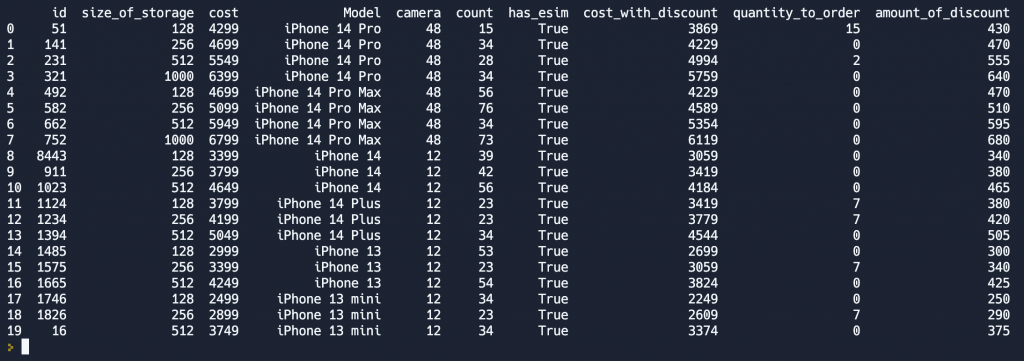
df['quantity_to_order'] = df['count'].apply(lambda value: 0 if value > 30 else 30 - value)Метод apply() можно применить не только к одному столбцу, но и к каждому ряду таблицы. При этом в функцию будет передан ряд. У нас есть столбец с полной стоимостью и со стоимостью со скидкой. Давайте на основе этих данных рассчитаем размер скидки.
def eval_discount(row):
return row['cost'] - row['cost_with_discount']
df['amount_of_discount'] = df.apply(eval_discount, axis=1)Обратите внимание на парамент axis=1, его необходимо передать, если мы хотим, чтобы в параметре row хранился именно ряд, а не отдельная ячейка из этого ряда.
Переименовывание колонок
Переименовать колонки поможет метод rename().
df.rename(
columns={'amount_of_discount': 'discount',
'cost': 'price'},
inplace=True
)Метод rename принимает словарь, ключ — имя колонки, которую нужно переименовать, значение — новое имя колонки. Если параметр inplace установлен в значение True, тогда изменится сам dataframe. Иначе будет возвращена копия dataframe с новыми именами колонок.
Если вам требуется переименовать все колонки, то проще обратится к свойству columns и перечислить новые имена колонок.
df.columns = ['new_name1', 'new_name2', 'new_name3']