Когда мы загружаем DataFrame из CSV файла, мы хотим знать как он выглядит. И для небольших таблиц можно использовать print(df), но если данных в таблице очень много можно распечатать только несколько первых строк. Для этого воспользуйтесь следующим синтаксисом.
print(df.head(5))В результате у ва на экран выведется первые 5 строк таблицы.
А для того чтобы вывести на экран информацию о типах данных хранящихся в каждом столбце, используйте код
df.info()Выбор колонки
Теперь мы знаем как загружать и создавать DataFrame. Настало время выбрать из серии данных интересующую нас информацию для её дальнейшей обработки. В коде есть созданный DataFrame с информацией о стоимости товара. Давайте выберем колонку ‘cost’ со стоимостью товаров, чтобы отсечь всю лишнюю информацию и сосредоточиться только на стоимости.
costs = df['cost']
print(costs)Альтернативный способ выбора колонки…
costs = df.cost
print(costs)При выборе колонки вы получите тип данных Series.
Оба способа выберут нужную нам колонку, но первый будет удобнее, если в наименовании нужной нам колонки присутствует пробел.
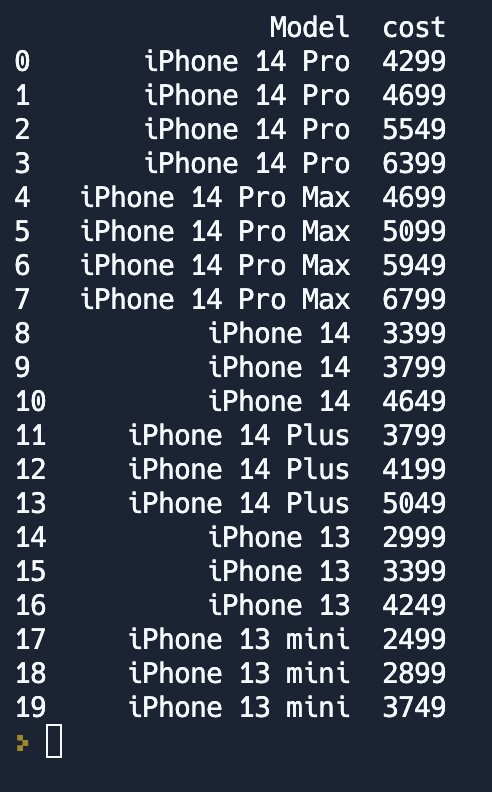
Видеть только стоимость не очень то удобно, хотелось бы понимать на какой товар установлена эта стоимость. Выбрать сразу несколько колонок из DataFrame можно используя список с названием нужных колонок.
model_and_cost = df[['Model', 'cost']]
print(model_and_cost)Результат работы этого кода вы можете видеть на рисунке справа. Таким образом мы убрали не интересующую нас информацию и оставили только самое нужное.
Выбор ряда
И так ориентируясь на стоимость мы можем уже выбрать интересующий нас товар и посмотреть его характеристики из основного DataFrame. Предположим нас интересует модель под индексом 4. Чтобы выбрать целиком ряд из df воспользуемся представленным ниже синтаксисом.
model = df.iloc[4]
print(model)Если же нам потребуется выбрать сразу несколько моделей подряд, можно указать с какого по какой индекс нам нужны ряды из таблицы. При этом второй индекс указывается исключительно.
models = df.iloc[4:7]
print(models)Таким образом у нас будут выбраны ряды под индексом 4, 5, 6.
Но зачастую позиции которые нужно выбрать находятся не на соседних рядах, а разбросаны по всей таблице. Предположим, нам нужно получить все модели телефонов не дороже 5000.
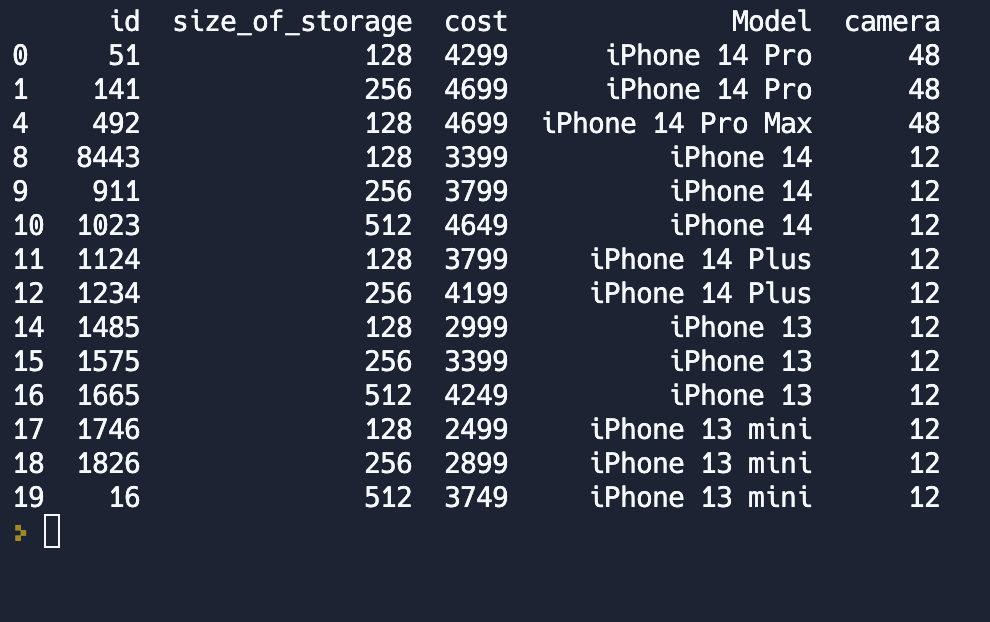
condition = df.cost < 5000
models = df[condition]
print(models)Сначала мы объявим переменную condition в которую запишем условие которому должна удовлетворять наша выборка. А затем применим этот фильтр к DataFrame в переменной df. Значения колонок можно сравнивать на равенство =, неравенство !=, больше >, меньше <.
Условия можно комбинировать используя операторы И &, ИЛИ |. Например, чтобы выбрать телефоны стоимостью до 5000 и это не iPhone 13 mini, мы можем написать такое условие.
condition = (df.cost<5000) & (df.Model != 'iPhone 13 mini')
models = df[condition]
print(models)Главное каждое условие обернуть в круглые скобки. Давайте ещё отберём только те модели у которых объём памяти 256Gb или камера 48Mpx.
condition = (df.size_of_storage==256) | (df.camera == 48)
models = df[condition]
print(models)В то же время, если мы хотим выбрать модели телефонов iPhone 13, iPhone 13 mini и iPhone 14, писать условие по отбору для каждой модели слишком громоздко. Если мы хотим отобрать записи по условию вхождения, следует объявить список моделей list_of_model и передать его в метод isin().
list_of_model = ['iPhone 13', 'iPhone 13 mini', 'iPhone 14']
condition = df.Model.isin(list_of_model)
models = df[condition]
print(models)Сбросим индекс
При выполнении примеров кода, возможно, вы обратили внимание на то, что таблицы которые мы получали в результате выборки имели индексы рядов основной таблицы. Если вы хотите заново проиндексировать таблицу, используйте метод reset_index().
models = models.reset_index()Но при использовании этого метода индексы старой таблицы никуда не удалятся, а перейдут в новый столбец. Для того чтобы избавиться от индексов исходной таблицы, задайте параметр drop в значение True.
models = models.reset_index(drop=True)
print(models)Series — это одномерная структура данных в библиотеке pandas. Она представляет собой индексированный массив с метками, который может содержать данные одного типа (числа, строки, булевы значения и т.д.). Series может быть создана из различных источников данных, включая списки, массивы NumPy или другие Series.
Каждому элементу в Series присваивается уникальный индекс, который позволяет обращаться к элементам по меткам. По умолчанию, индекс начинается с нуля, но можно определить пользовательский индекс.
Series обладает мощными возможностями для манипуляции данными, включая фильтрацию, сортировку, агрегацию, применение функций и многое другое. Она является важной частью работы с данными в pandas и часто используется вместе с DataFrame для анализа и обработки данных.