В этой главе мы поговорим о агрегатных функциях в библиотеке pandas. Агрегатные функции это способ получить статистику из группы входных данных в виде одного числа. В основном статистические данные включают такие показатели как: среднее значение, медиану и стандартное отклонение. Вы также узнаете, как преобразовать DataFrame в сводную таблицу, что является отличным способом сравнения данных в двух измерениях.
Сбор статистики по колонке.
Наш dataframe содержит колонку Model, в которой имеются повторяющиеся значения и для того чтобы посчитать сколько в нашей таблице уникальных значений, можно воспользоваться методом nunique().
print(df.Model.nunique())А для того чтобы получить эти самые значения, используйте метод unique().
unique = df.Model.unique()
print(unique)Общий синтаксис для всех методов одинаков. Сначала обращаемся к столбцу и через точку применяем один из следующих методов.
| метод | описание |
|---|---|
mean() | среднее арифметическое среди всех значений в колонке |
std() | среднее отклонение от среднего арифметического значения |
median() | медиана (значение находящееся в середине среди упорядоченного списка) |
max() | максимальное значение в колонке |
min() | минимальное значение в колонке |
count() | количество значений в колонке |
unique() | перечень уникальных значений |
nunique() | количество уникальных значений |
Группировка данных
Давайте представим себе такую задачу. В таблице представлены несколько моделей телефонов, но стоимость каждого из них отличается в зависимости от объёма памяти. Как получить среднюю стоимость за каждую представленную линейку моделей телефонов? Или узнать стоимость самого дорого телефона в каждой линейке? Можно написать сложные алгоритмы по отбору каждой модели и расчёту средней стоимости, но pandas предлагает более элегантное решение.
mean = df.groupby('Model').cost.mean()
print(mean)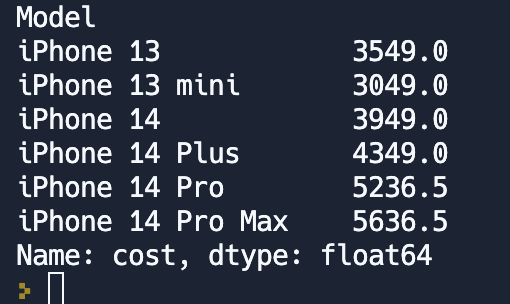
Сначала мы сгруппируем (свернём) таблицу по одинаковым значениям в стобце Model. А затем к столбцу cost в разрезе сгруппированных значений применим метод mean(), который покажет нам среднее арифметическое для каждого свёрнутого значения.
Синтаксис имеет следующий вид df.groupby(столбец_для_группировки).столбец_по_которому_получим_результат.метод_расчёта_результата()
Однако, если вы обратите внимание, в результате метода groupby() нам вернётся объект класса Series, а если мы хотим получить новый DataFrame, нужно применить метод reset_index(). Тогда мы снова сможем работать с получившейся выборкой как с отдельным DataFrame.
Давайте получим таблицу со стартовыми ценами на каждую линейку телефона.
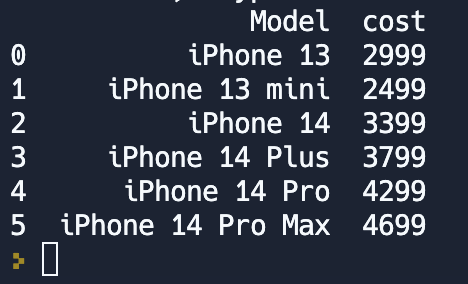
start_price = df.groupby('Model').cost.min().reset_index()
print(start_price)Группировать можно сразу по нескольким полям. Для этого в метод groupby() нужно передать список столбцов, по которым вы хотите произвести свёртку.
new_df = df.groupby(['size_of_storage', 'camera']).id.count().reset_index()Данный код свернёт данные по уникальным значениям Размера хранилища и камеры. И в разрезе этих значений мы посчитаем сколько моделей представлено.
Переименуем поле id так как оно не отображает суть информации которая хранится в этом столбце.
new_df.rename(columns={'id':'count_of_model'}, inplace=True)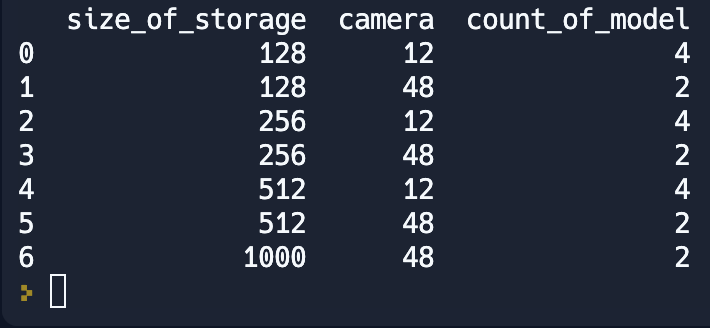
Сводные таблицы
Когда мы группируем данные по нескольким полям, иногда удобно отображать полученный результат в немного другой форме. В данном случае успешно будет применить шахматку.
pivot_count_of_model = new_df.pivot(
columns='camera',
index='size_of_storage',
values='count_of_model'
).reset_index()
print(pivot_count_of_model)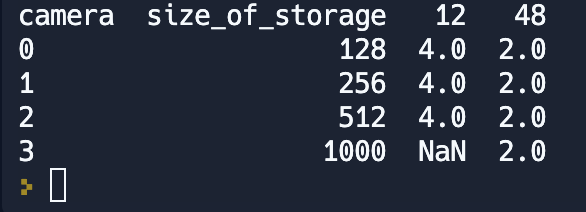
columns — то что будет отображаться в колонках
index — что будет располагаться в рядах
values — значения, которые будут располагаться на пересечении ряд-столбец.