У нас есть две таблицы. Одна с телефонами, другая с количеством проданных товаров. Взгляните на каждую из них. Из каждой создайте dataframe.
iphones = pd.read_csv('iphones14.csv', sep=';')
sales = pd.read_csv('sales.csv', sep=';')
print(iphones)
print(sales)Внутреннее соединение
При любом соединении у таблиц должно быть общее поле по которому будут сопоставляться записи из одной таблицы с записью из другой. В нашем случае — это поле id. Однако, прежде чем выполнить код, обратите на количество записей в таблице sales и таблице iphones.
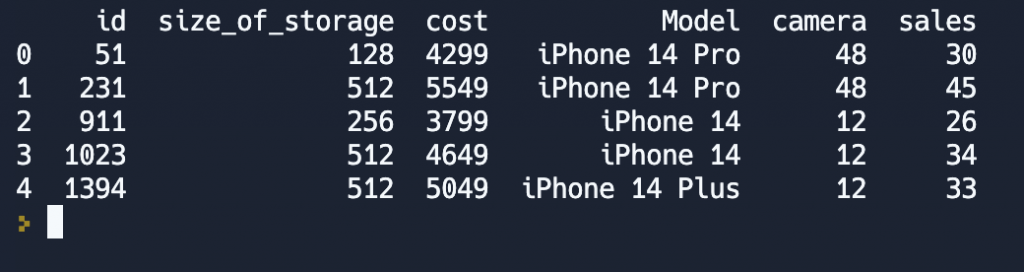
new_df = pd.merge(iphones, sales)
print(new_df)При внутреннем соединении в результирующую таблицу попадают только те записи, у которых есть записи с одинаковым id в обеих таблицах, а все остальные записи, которым не нашлось пары в соседней таблице, просто отсеятся.
В итоге мы видим только те телефоны, о которых есть информация о продажах. И мы не видим информации о продажах тех товаров, которых нет в dataframe iphones.
Того же самого результата можно добиться используя следующий синтаксис.
new_df = iphones.merge(sales)Соединять можно больше двух таблиц, просто несколько раз примените метод merge().
big_df = table1.merge(table2).merge(table3)На одном из прошлых уроков мы рассчитали необходимое количество для заказа на новогодние праздники. Результат этих расчётов хранится в таблице orders.csv. Преобразуйте её в dataframe и попробуйте соединить внутренним соединением с iphones.
orders = pd.read_csv('orders.csv', sep=';')
new_df = pd.merge(orders, iphones)Представленный выше код приведёт к ошибке
pandas.errors.MergeError: No common columns to perform merge on. Merge options: left_on=None, right_on=None, left_index=False, right_index=FalseВсё дело в том, что у этих таблиц нет одноимённых столбцов и необходимо явным образом указать по каким столбцам мы будем производить слияние.
orders = pd.read_csv('orders.csv', sep=';')
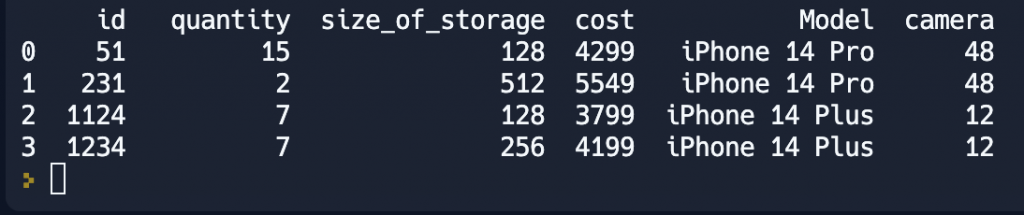
new_df = pd.merge(orders, iphones, left_on='product', right_on='id')Либо на время переименовать название столбца product в id.
new_df = pd.merge(orders.rename(columns={'product':'id'}), iphones)Результат работы будет одинаковым и представлен на рисунке ниже
Сложение таблиц
Никогда не путайте соединение таблиц и их сложением. При соединении в таблице увеличивается количеств столбцов и она растёт в ширину, а при сложении увеличивается количество строк и таблица растёт в высоту. Только что мы выполняли несколько соединений таблиц и у нас появлялись столбцы с информацией о количестве продаж и необходимом количестве заказа.
Иногда, для удобства хранения, данные разбиваются на несколько идентичных таблиц. Так их проще структурировать и хранить, но при обработке, данные нужно собрать все вместе в один dataframe из разбитых файлов. Главное правило при сложении двух таблиц — чтобы количество и имена колонок совпадали. Поэтому заранее позаботьтесь об этом.
У нас есть таблицы iphones13.csv и iphones14.csv, и для того чтобы их объединить в один файл используется функция concat().
iphones13 = pd.read_csv('iphones13.csv', sep=';')
iphones14 = pd.read_csv('iphones14.csv', sep=';')
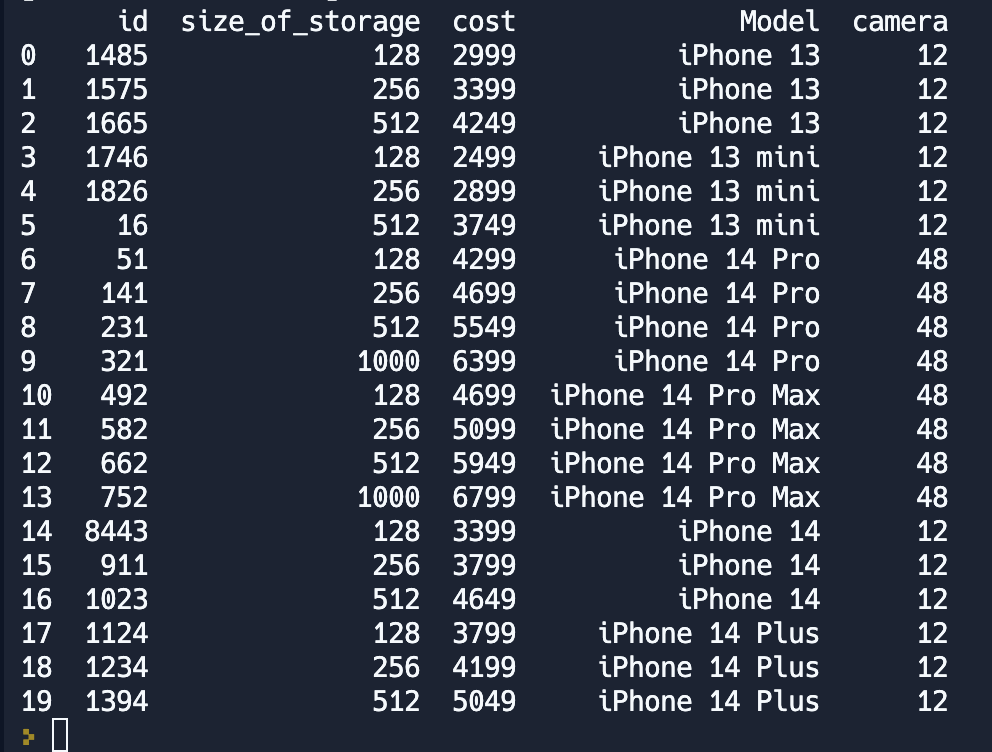
iphones = pd.concat([iphones13, iphones14]).reset_index(drop=True)
print(iphones)В итоге мы получили таблицу аналогично той, что мы использовали в предыдущих статьях.
Внешнее соединение
Пару шагов назад для таблиц sales и iphones мы применяли внутреннее соединение, при этом все записи, которые не нашли себе пару по id, удалялись из обоих таблиц. Внешнее соединение позволяет избежать этого и оставляет все записи из каждой сливаемой таблицы.
all_sales = pd.merge(iphones, sales, how='outer')
print(all_sales)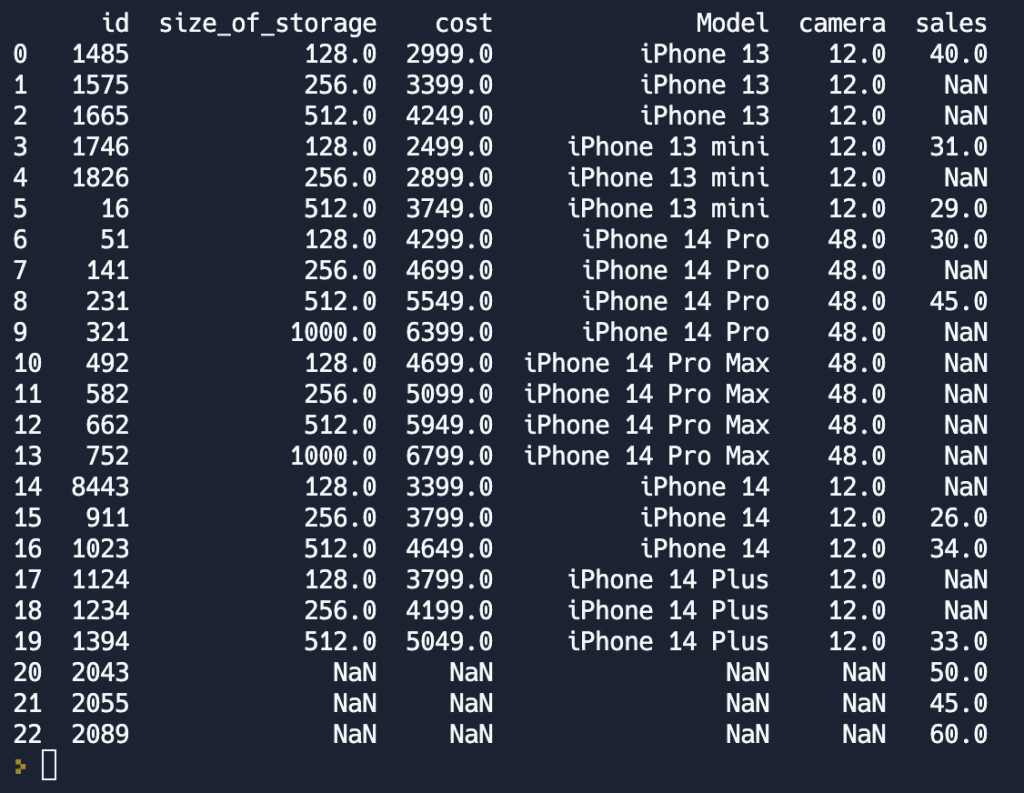
Обратите внимание на то, что в записях, которым не нашлось пары по id, записывается значение None. Последние три строки с id 2043, 2055, 2089, говорят о том, что у нас есть информация о том, сколько товара было продано по указанному id, но характеристики этого товара хранятся, скорее всего, в другой таблице. А нужны ли нам эти записи?
Левое соединение
При левом соединении в результирующую таблицу гарантированно попадут все записи из левой таблицы, а из правой, только имеющие общий id. Таким образом мы можем избавиться от полупустых строк получившихся в результате внешнего соединения.
iphone_sales = pd.merge(iphones, sales, how='left')
print(iphone_sales)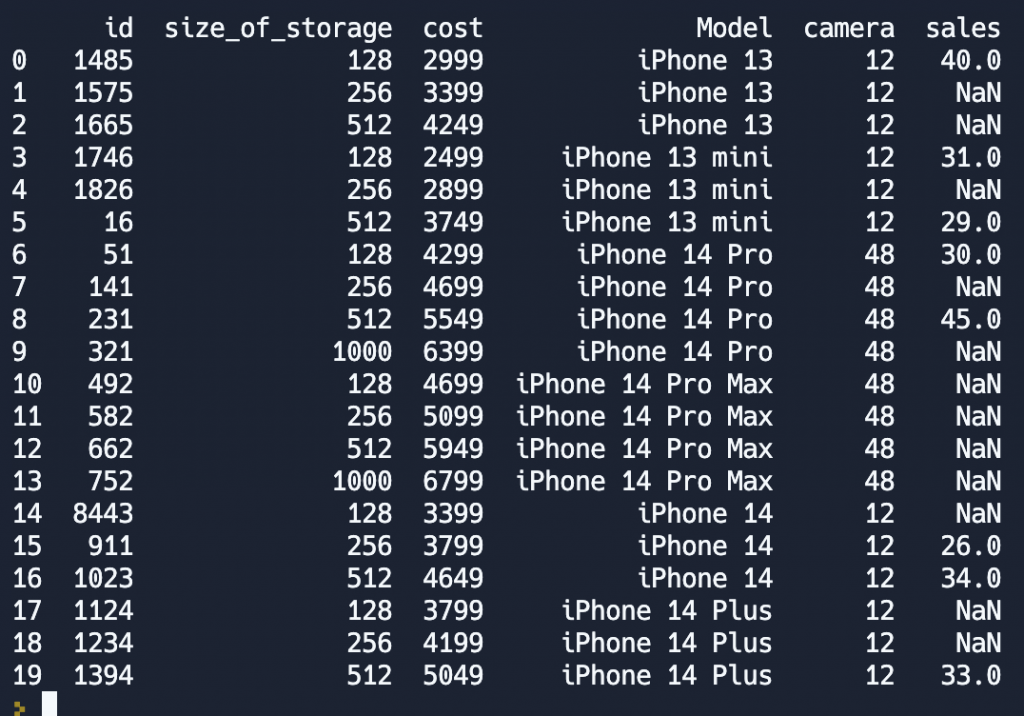
Не забывайте, если имена столбцов при слиянии отличаются, используйте параметры left_on=», right_on=», для того чтобы явно указать названия столбцов, по которым необходимо выполнять сравнения.